


Introduction
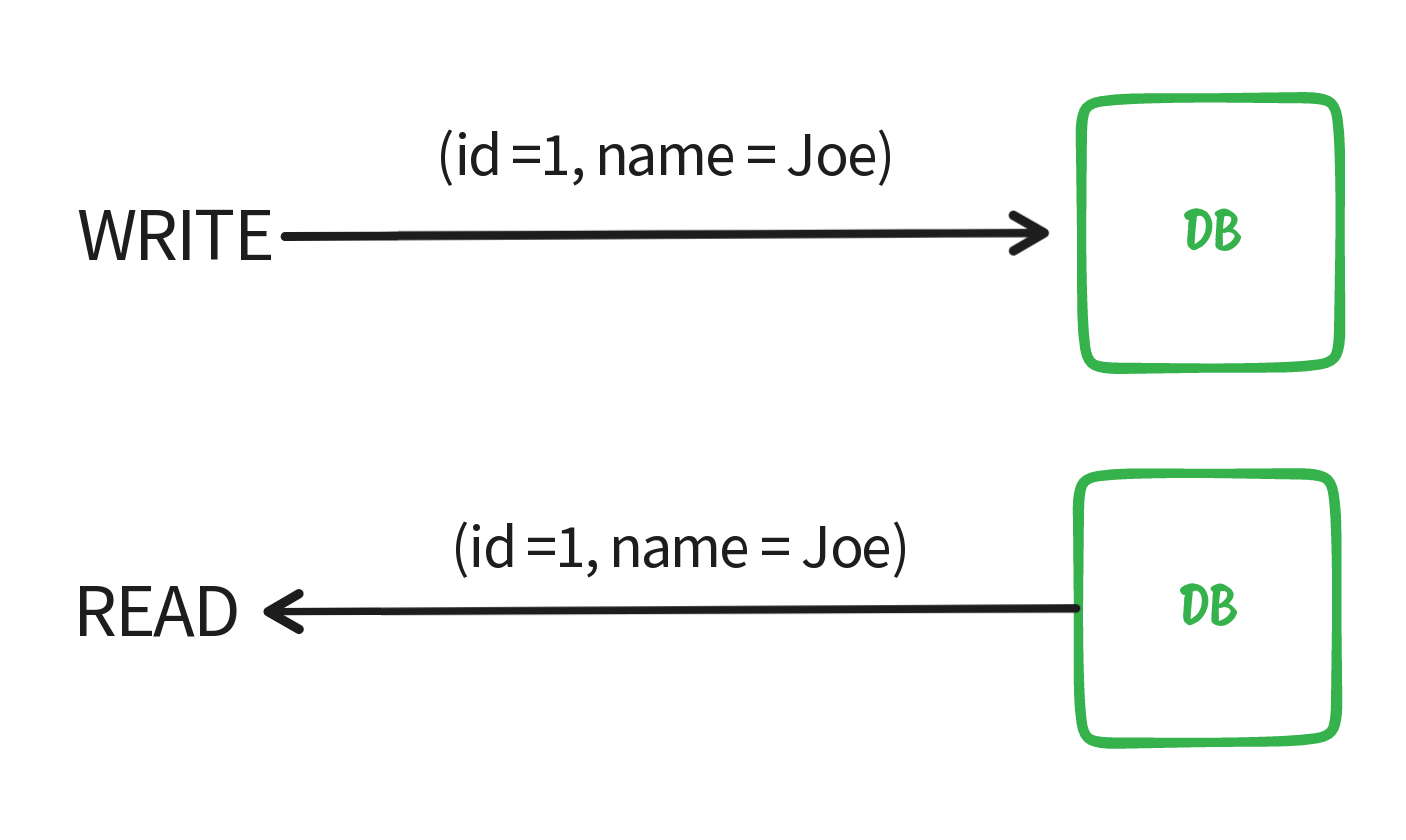
First of all, we have to define what is data consistency, Given that you update a record x with a new value every subsequent read for the same record should display the new value not the old value.
Consistency In SQL
In the SQL world, data consistency is pretty straightforward, since SQL usually supports vertical scaling so given that you write a single SQL statement (which is considered a transaction) all the subsequent reads should read the new value.
UPDATE employees
SET NAME = 'Joe'
WHERE id = 1;
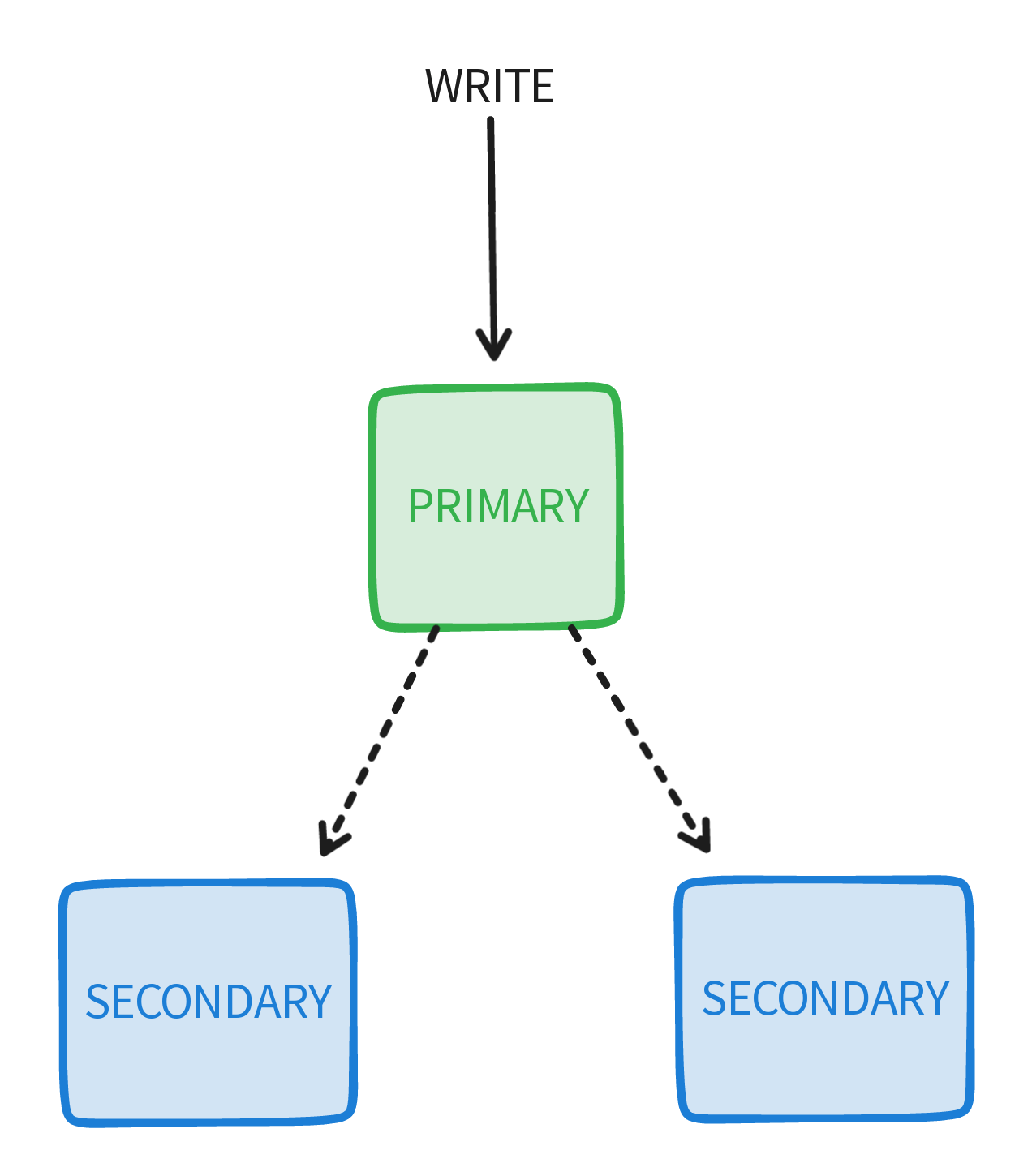
NoSQL Cluster
Since most NoSQL databases support horizontal scaling having replicas and data redundancy for backup and availability is pretty common. We will use mongo as our case study.
A standard mongo replica usually consists of an odd number of nodes, a replica has one primary node and all other nodes are considered secondary nodes possibly with different roles (arbiter node, delayed node, ...). All the writes go through the primary node and then it replicates the data to secondary nodes asynchronously.
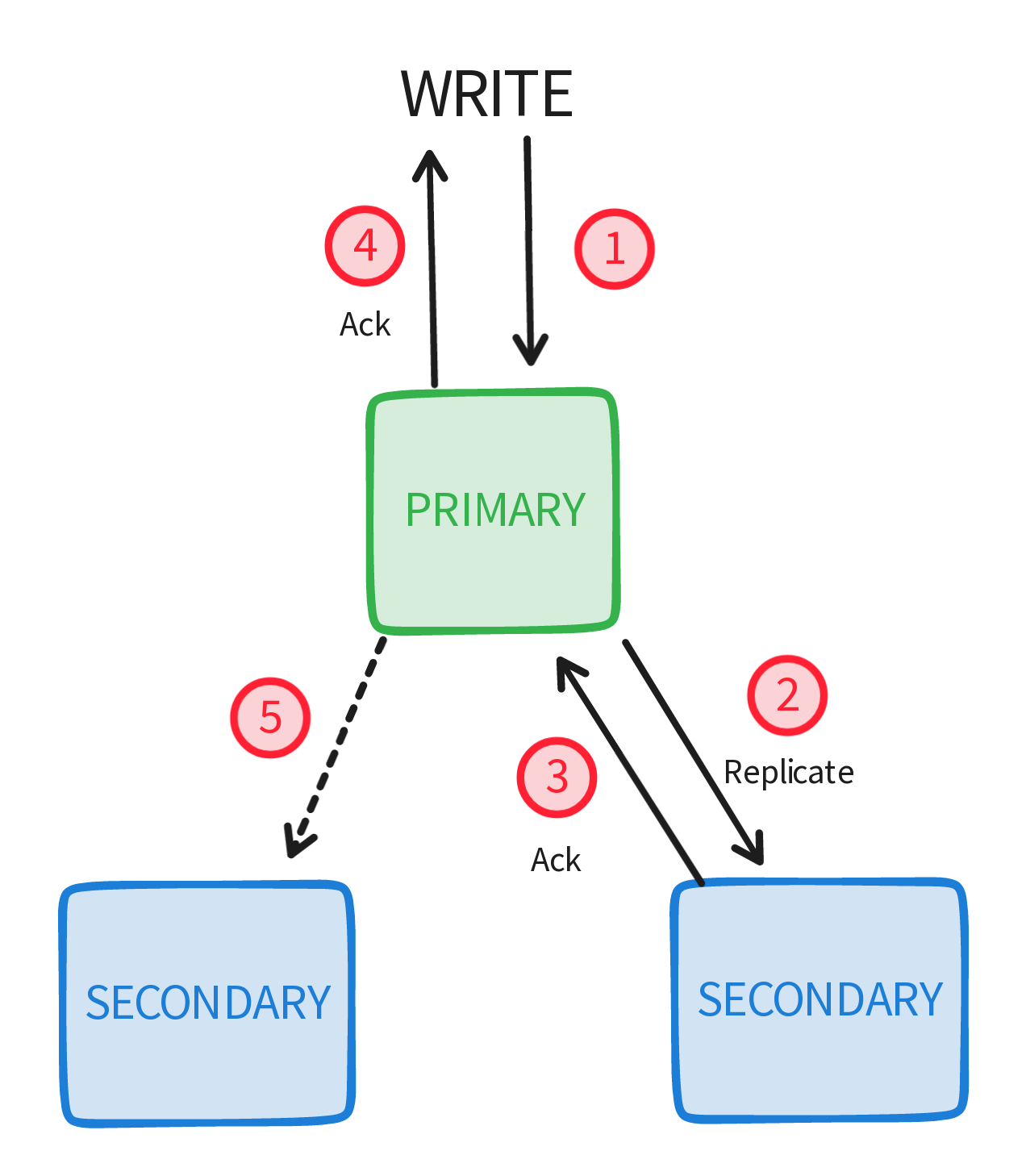
Handling Node Failures
Since our cluster can have multiple nodes some of them might fail (primary or secondary), if the primary fails a node election starts so a new node can act as the primary node (usually the node with the newest data becomes the primary node) if a certain number of nodes fail (the majority) the cluster turns into a read-only cluster. What exactly is the majority when it comes to mongo? the majority is equal to the number of ceil of (nodes / 2) , if the number of failing nodes is equal to the majority or more like we said the remaining nodes turn into read-only nodes.
| Number of nodes | Majority | Maximum Number Of Failing Nodes |
| 1 | 1 | 0 |
| 2 | 1 | 0 |
| 3 | 2 | 1 |
| 4 | 2 | 1 |
| 5 | 3 | 2 |
If you noticed the maximum number of failing nodes in a cluster of size 3 is the same as a cluster of size 4 this is why usually a cluster has an odd number of nodes since the added benefit in terms of availability is the same (same maximum number of failing nodes). So If data was written/updated to the primary and the node failed before replicating that data, when it comes back up that write/update might rollback (the primary node will remove the new data so it's in sync with the rest of the replica).
Achieving Data Durability In NoSQL
So let's say you have a cluster of 3 nodes, and we perform a write/update operation on our data, as we said all our writes go to the primary node and are then replicated to the secondary nodes, but what happens if the primary node crashes before replicating that data ??. That data is lost, any reads after that will return the old data.
That's why NoSQL databases allow different kinds of write durability levels, in mongo for example when issuing a write or update query you can configure the number of acknowledgment returned to determine the success of the write operation (write concern):
<number>: it could be an arbitrary number like 1 (lowest level of durability) so you only need an acknowledgment from the primary node.majority: which requires a number of acknowledgment equal to the majority (in our case that's 2) The majority level provides the highest level of data durability by that I mean that once the write is successful it's guaranteed that the new data will never rollback or be lost.
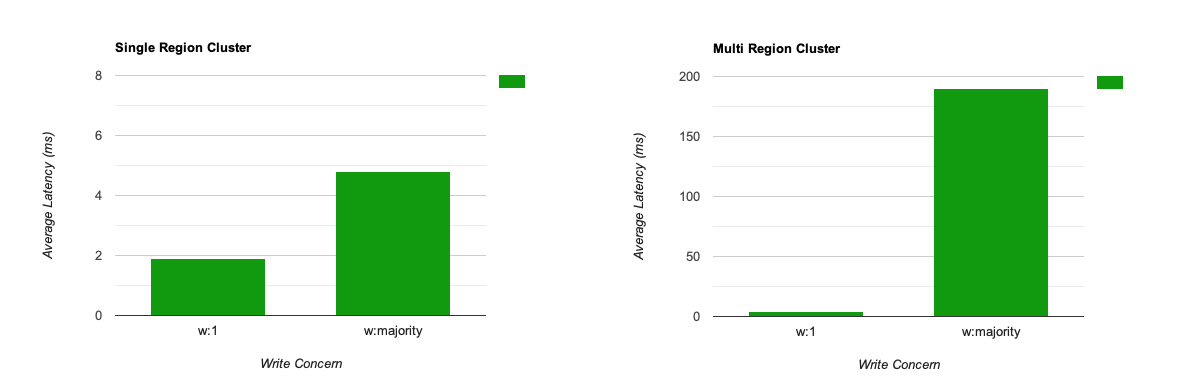
The disadvantage of a higher level of durability, is the slow writes, The more acknowledgments that you need from the replica the higher the latency. According to the mongo atlas, these are the average latencies for the different write levels:
Read Preference In NoSQL
Since our replica consists of many nodes, it's up to the developer to decide which node will be used for reading data. Mongo has multiple options for specifying which type of node should respond to the read query by choosing the adequate read preference:
primary: Default mode, forwards all read queries to the primary node.primaryPreferred: If the primary is available read from it, else read from the secondary nodes.secondary: Read from the secondary nodes.secondaryPreferred: If the secondary nodes are available read from them, else read from the primary nodenearest: Read from the nearest node in terms of minimum network latency regardless of the type of the node be it primary or secondary.
Depending on our application we might need to read from secondary nodes, if our application has a lot of writes then the primary node might have a lot of work to do (handling writes, replicating the data, and handling read queries). So we can offload some of that work by forwarding read requests to secondary nodes.
Since data is asynchronously replicated from the primary to the secondary nodes, there might be a delay between writing to the primary node and the primary node replicating to the secondary nodes so if we are reading from the secondary nodes we might read stale data, so there has to be a way of achieving certain levels of consistency if needed.
Achieving Read Consistency In NoSQL
Motivation
Now that we know we can make our writes durable using the majority write concern that doesn't mean all our write operations will necessarily use it, even if so some problems will occur, so what are these problems and what does mongo offer as a solution?
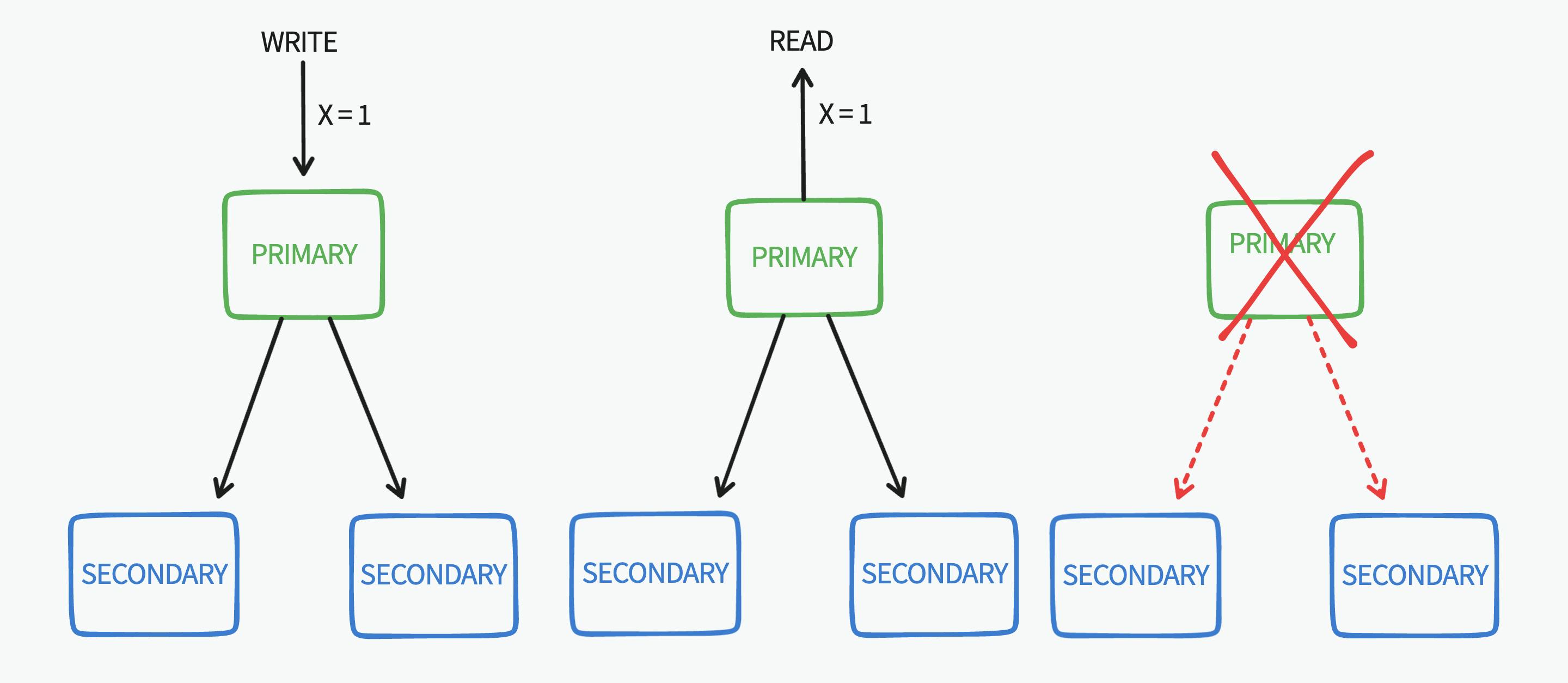
Primary Node Failure
When performing a write operation on the primary node using the default write concern the write is acknowledged after it's persisted on the primary node only, if a read operation follows our write operation on the primary node it will get the new data, If the primary node fails before replicating the data to the other nodes it's lost any other read following that failure will not retrieve that new data (inconsistent read operations given no new write operations)
Replication Lag
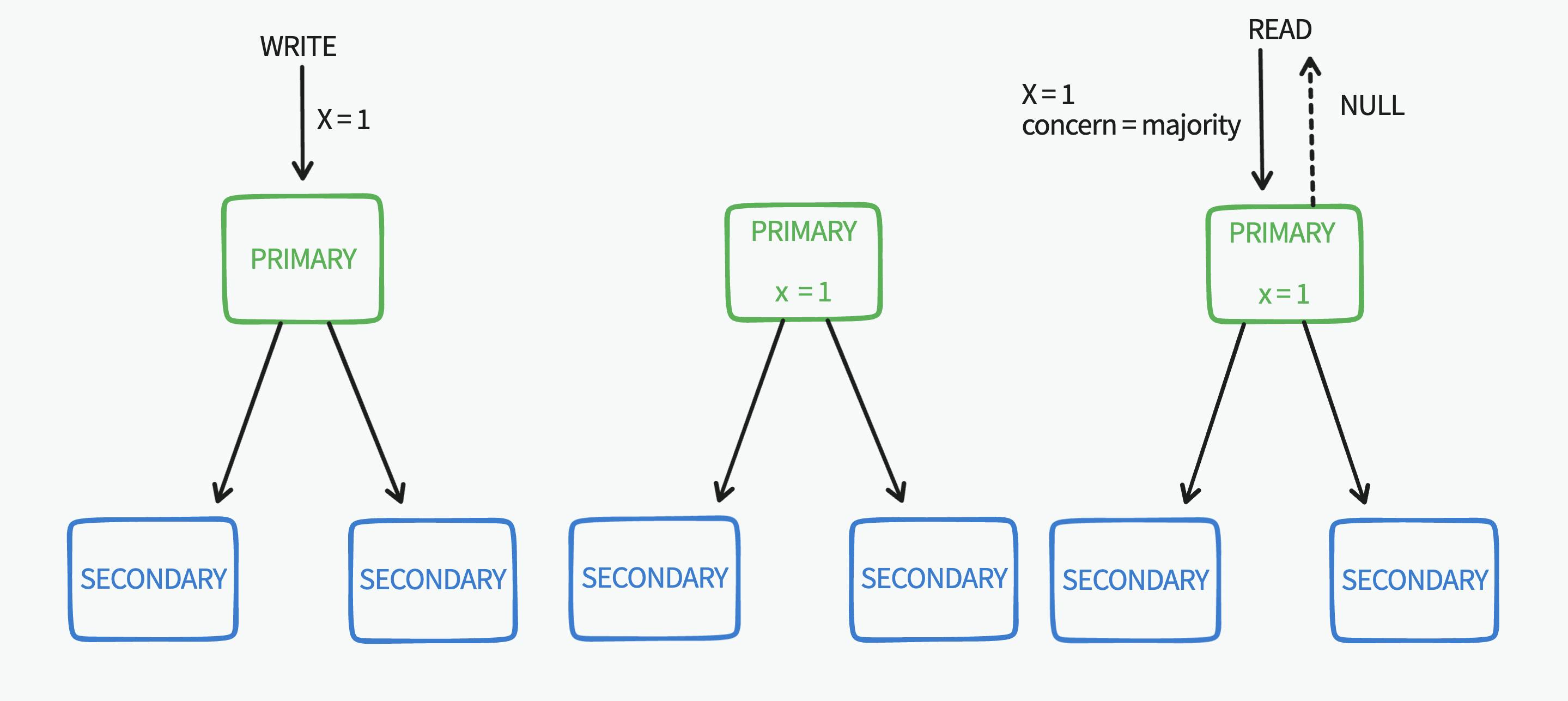
Even if we use write concern majority in the case of a replica set with 3 nodes the write is only replicated to 2(majority) of the 3 nodes. After the write operation is acknowledged any subsequent read operation with read preference secondary it might read from the secondary node that has the new write operation or it might read from the other secondary node (the same two read operation reading different data)
Read Concern
The first problem occurred because the write operation on the primary node was made using the default write concern, as we can see that data can be rolled back (not durable). mongo's read concern allows us to read data of certain durability level when needed. We will focus on local, majority, and linearizable only:
local: (Default mode) Local read concern fetch the newest data on the corresponding node regardless of how durable it is (the data might be replicated to the other nodes or it might rollback). This resembles the isolation levelREAD UNCOMMITEDin SQL.majority: fetches data that is only replicated to the majority nodes of the replica (that are 100% durable and won't roll back) This resembles the isolation levelREAD COMMITTEDin SQL.linearizable: Like majority, it returns data that is only confirmed to be committed to the majority of the replica set, the main difference is when issuing the query with this read concern, if there are any concurrent write operations running it will wait until they propagate to the majority of the replica set. So in some cases, it's way slower than majority.
For our first problem if we use read concern majority, it will not read the new data as it's not yet replicated to the rest of the set's majority, so we won't be fetching the newest data as it's not durable yet
After the primary node replicates that write operation asynchronously it will be durable, so. if we repeat the same read operation using majority concern it will be returned (although the same read operations returned different data this was due to the new write operation taking effect and being committed to the majority of the replica).
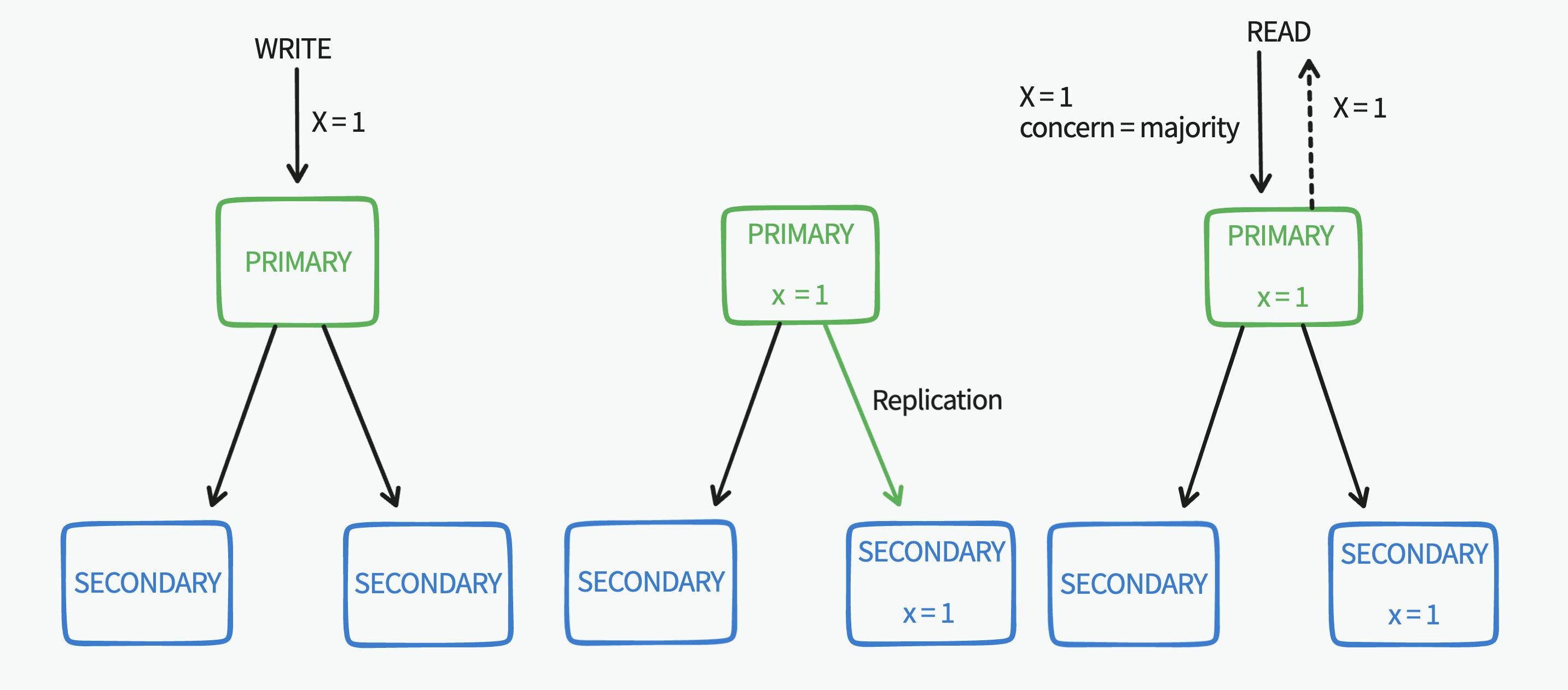
As for the second problem, we have two options:
We can read the data from the primary node using read concern majority since all the write operations go through the primary node it's aware of all the write operations and if they are majority committed or not, so this option will return the newest durable data possible.
We can use the
linearizableread concern, as it waits for concurrent writes to be committed so this option will also allow us to read the newest durable data possible.
Conclusion
By using the different levels for write concern and read concern in mongo we can achieve the following:
- Make our write operations durable (not rollback in case of node failure) using write concern majority
- Read durable data that might not be the newest data using read concern majority on secondary nodes
- Read the newest durable data using read concern majority on the primary or linearizable on the secondary nodes